NY Times topics in OPML, the mother lode? ![]()
 Amyloo was digging around the NY Times code weblog and found this OPML file, weighing in at a monstrous 3.3MB that contains some mysterious but rich data about the NY Times and a guide to using the Times to cover special topics that I don’t think anyone outside the Times knew existed, but there it is, in a public folder, so lets have a look.
Amyloo was digging around the NY Times code weblog and found this OPML file, weighing in at a monstrous 3.3MB that contains some mysterious but rich data about the NY Times and a guide to using the Times to cover special topics that I don’t think anyone outside the Times knew existed, but there it is, in a public folder, so lets have a look.
1. There are 10522 top-level headlines. There’s no structure to the OPML, it’s absolutely flat.
Here’s an HTML rendering of the list: timestopics.html.
2. It’s a subscription list. Each item has four attributes, type, title, htmlUrl and xmlUrl.
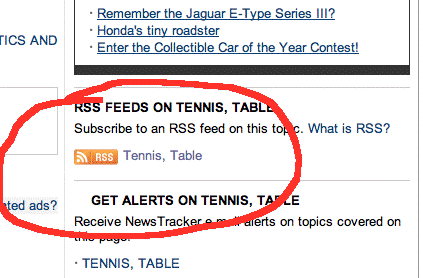
3. The htmlUrl for each element points to a page of stories for the topic. For example, here’s a page of stories about table tennis. On that page is a link to an RSS 2.0 feed containing the same information.
4. The xmlUrl links for at least some of the elements are broken, the error appears to be very simple, if you replace the ampersand with a question mark, it works.
If you look around at the topics you’ll see it’s an incredibly rich set of data. Here are just some of the topics that begin with the letter T: Tableware, Taste, Tattoos, Tax Credits, Tax Evasion, Taxation, Taxicabs and Taxicab Drivers, Tea, Teachers and School Employees, TED Conference News, Teflon, Telephones and Telecommunications, Television, Television Sets, Table Tennis, Terra Cotta, Terrorism, Tests and Testing, Textbooks, Thanksgiving Day.
NY Times metadata ![]()
 If you do a View Source on a NY Times story, you’ll see that there’s lots of metadata in the HTML, including keywords for most of the of the stories.
If you do a View Source on a NY Times story, you’ll see that there’s lots of metadata in the HTML, including keywords for most of the of the stories.
Behind the keywords is a taxonomy that I haven’t seen, but would like to. I asked them to make this public, both at my meeting there last Thursday and in a phone talk this morning. I think there could be a lot of value in the Times taxonomy, it might even set a standard.
In the meantime, I wrote a script last night that tracks the keywords in NY Times stories as they flow through the nytimesriver application. Here’s a report that’s updated once per hour.
http://nytimesriver.com/keywords.html
Obviously it would be interesting to be able to click on the keywords to see what articles reference each of the keywords. And it would also be nice to have a cumulative list and a daily list. Right now all we have is the cumulative version.
But it’s still pretty interesting, bordering on fascinating to think of the possibilities if they provide the framework behind these keywords.
When the pros try to figure out how what they do will continue to make sense after the Internet achieves all its promise, this may be an example. The metadata is generated by librarians, and we don’t as yet have our own librarians in the blogosphere (though some might disagree). And it’s possible that after a release of the taxonomy that something like Wikipedia may happen, with the public taking over maintenence of the taxonomy. No one knows what will happen, but one thing seems clear, there can be value in a news organization beyond the reporting and editing it does.
Unsung flow-builders ![]()
Over the last week, I’ve been writing about the disconnect between flow and rank. Paradoxically, sites that are ranked high don’t always deliver a lot of hits when they link to you.
On the flipside, there are some sites that are rarely on Top 100 lists, or talked about very much, that deliver substantial flow. Two of them stand out, one a veteran site, and the other a relative newcomer.
 1. Daring Fireball is a thoughtful blog written by John Gruber that focuses on the Macintosh. Since I’ve returned to the Mac in 2005, and have been writing more about Mac issues, I’ve started getting links from this site, and when I do, they usually send between 1000 and 2000 readers my way. And they’re generally interesting people with useful information and ideas. I follow Gruber on Twitter and have learned that he is a Phillies fan and therefore disappointed this year. His posts are interesting there too, and irreverent, which I like of course. 🙂
1. Daring Fireball is a thoughtful blog written by John Gruber that focuses on the Macintosh. Since I’ve returned to the Mac in 2005, and have been writing more about Mac issues, I’ve started getting links from this site, and when I do, they usually send between 1000 and 2000 readers my way. And they’re generally interesting people with useful information and ideas. I follow Gruber on Twitter and have learned that he is a Phillies fan and therefore disappointed this year. His posts are interesting there too, and irreverent, which I like of course. 🙂
2. A Digg-like memetracker, news.ycombinator.com is in the same league as TechMeme, about 1000 hits for a highly ranked piece. I don’t know much about the site, I’m not a regular reader, and I don’t know much about the people who visit from this site.
iPhone SDK coming in Feb ![]()
Apple announced that there will be an SDK for the iPhone.
Hooray!
Funny sign at Web 2.0 ![]()

Thanks to Bijan Sabet!
Nokia N810 ![]()

Just read about this on Engadget.
I know there’s a Nokia breakfast in SF starting at 8AM, which I will not be able to make, but as an N800 user, if this product really is coming, I can see two thing right off the bat that address major problems with the previous model. 1. Nokia makes good keyboards, but the old model doesn’t have one. On-screen keyboards are a pain, even relatively good ones like the one in the iPhone, but the one in the N800 is not particularly good. 2. The other notable feature is the screen resolution, which looks pretty fantastic.
Anyway, I’ve asked my contacts at Nokia for info as soon as it’s available, but it seems like the Engadget guys are on top of it. If you have any more info, please post a comment here. Thanks.
Later…
Nokia did announce the N810 (data sheet pdf).
Here’s a high-res picture.
A video showing the N810 in action.
Flors: What the N810 means for maemo developers.
Apple’s iPhone SDK announcement ![]()
Note: There was no permalink for the story on Apple’s news website, here’s the full text, with permalink. DW
Let me just say it: We want native third party applications on the iPhone, and we plan to have an SDK in developers’ hands in February. We are excited about creating a vibrant third party developer community around the iPhone and enabling hundreds of new applications for our users. With our revolutionary multi-touch interface, powerful hardware and advanced software architecture, we believe we have created the best mobile platform ever for developers.
It will take until February to release an SDK because we’re trying to do two diametrically opposed things at once—provide an advanced and open platform to developers while at the same time protect iPhone users from viruses, malware, privacy attacks, etc. This is no easy task. Some claim that viruses and malware are not a problem on mobile phones—this is simply not true. There have been serious viruses on other mobile phones already, including some that silently spread from phone to phone over the cell network. As our phones become more powerful, these malicious programs will become more dangerous. And since the iPhone is the most advanced phone ever, it will be a highly visible target.
Some companies are already taking action. Nokia, for example, is not allowing any applications to be loaded onto some of their newest phones unless they have a digital signature that can be traced back to a known developer. While this makes such a phone less than “totally open,” we believe it is a step in the right direction. We are working on an advanced system which will offer developers broad access to natively program the iPhone’s amazing software platform while at the same time protecting users from malicious programs.
We think a few months of patience now will be rewarded by many years of great third party applications running on safe and reliable iPhones.
Steve
P.S.: The SDK will also allow developers to create applications for iPod touch. [Oct 17, 2007]

{kind=link}
{kind=link}
Posted by g. on October 17, 2007 at 11:22 am
Well there were press photos and a first preview on the Tabletblog – apparently the guy already has one…
Posted by g. on October 17, 2007 at 11:23 am
I’m talking about the n810 of course.
Posted by Jason Etheridge on October 17, 2007 at 1:01 pm
Will it ever make sense to have a multi-level taxonomy (i.e., categories within categories), or do tags imply that it’ll always be effectively flat? I realise the same effect can be approximated by applying multiple tags to a given item (or story in this case), such as “Athletics and Sports” and “baseball”.
Whenever I’ve thought about this, I find there’s an initial mental hurdle to overcome that’s based on the traditional hierarchical arrangement of information… then I get over it. Attaching whatever tags are applicable is so much more powerful. I agree with Weinberger: everything really is miscellaneous. 🙂
Posted by Dave Winer on October 17, 2007 at 1:02 pm
I believe they have a hierarchic taxonomy at the Times, we’re just seeing a flattened out rendering of it in the keywords. I’m trying to get them to publish the full thing.
Posted by Ryan on October 17, 2007 at 1:06 pm
So there’s a database behind it somewhere and they’re not just indexing those keywords for search?
Posted by calvin on October 17, 2007 at 1:24 pm
Dave,
news.ycombinator.com is associated with Paul Graham. according to Graham, news.ycombinator.com is running the(his) lisp(ish) software Arc. Ycombinator is the venture/investment firm Graham participates in and writes about in some of his essays.
Many of the articles I’ve seen on news.ycombinator.com are startup related.
Posted by Amyloo on October 17, 2007 at 1:47 pm
I noticed a topical OPML file at the NYTimes geek site you pointed to a week ago or so. Was going to play with a search of it. Do the keywords map to that structure, I wonder?
Posted by Dave Winer on October 17, 2007 at 1:48 pm
Amy, do you have a URL for the file??
Posted by Ian Kennedy on October 17, 2007 at 2:08 pm
I really *must* show you a hack that I did for Yahoo’s internal hack day last week. It’s a tag cloud of the nytimes.com taxonomy based on traffic flows across the 200k+ sites that feature the MyBlogLog widget.
Also check out this work by Aaron Cope on this. I learned about him from a comment he left on my post about the nytimes metadata.
http://aaronland.info/nytimes/
Posted by amyloo on October 17, 2007 at 2:23 pm
Here we go:
http://code.nytimes.com/downloads/topics-opml.xml (3.3MB)
From an open directory listing that has some other interesting looking files in it:
http://code.nytimes.com/downloads/
Posted by Wes Felter on October 17, 2007 at 3:06 pm
Developer info for the N810: http://flors.wordpress.com/2007/10/18/what-the-nokia-n810-means-for-maemo-developers/
Posted by Phong Le on October 17, 2007 at 4:28 pm
I don’t get it. If we’re supposed to be in favor of open source, cross-platform applications, why are we cheering an iPhone SDK? Shouldn’t we encourage more AJAX web apps?
Posted by Simon Fodden on October 17, 2007 at 7:19 pm
It’s cool that the OPML file gives us the whole list together. But the Times Topics page (http://topics.nytimes.com/top/reference/timestopics/) has always offered a straightforward way in, no?
Posted by Jakob on October 19, 2007 at 2:48 am
Managing taxonomies by crowds like managing an encyclopaedia in Wikipedia is probably worth a try but first the task is to make available any taxonomy at all. I recently wrote something about taggi g enriched with controlled vocabularies: Up to now tagging applications (or any other web based application for manual indexing) just don’t support controlled vocabularies in a useful way. I hope that this will improve with SKOS in the next years.
It’s mostly a matter of the interface: Tagging gained success a lot because easy interfaces for everyone and not because of the new concept behind it.
BTW: Why don’t you post different topic articles as single blog entries?!